Notes on VAEs, diffusion models, GANs, and other generative approaches. Covers theory, architectures, and training techniques for generation tasks.
This section covers the core families of generative models used in modern machine learning. Notes begin with the foundational variational autoencoder (VAE) and its extensions (importance-weighted objectives, contrastive priors), then move through continuous normalizing flows, neural ODEs, score-based and diffusion models, and flow matching. The thread connecting these works is the shared goal of learning to sample from complex distributions, and each set of notes tries to make the mathematical connections between approaches explicit rather than treating them as isolated methods.
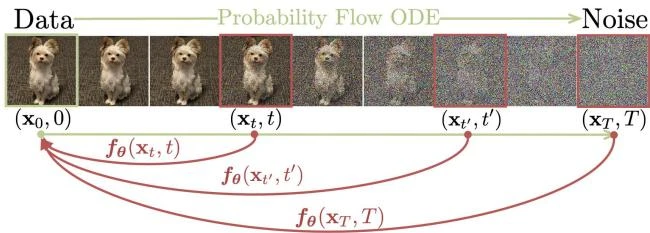
Consistency Models: Fast One-Step Diffusion Generation
This paper introduces consistency models, a new family of generative models that map any point on a Probability Flow ODE trajectory to its origin. They support fast one-step generation by design, while allowing multi-step sampling for improved quality and zero-shot editing tasks like inpainting and colorization.
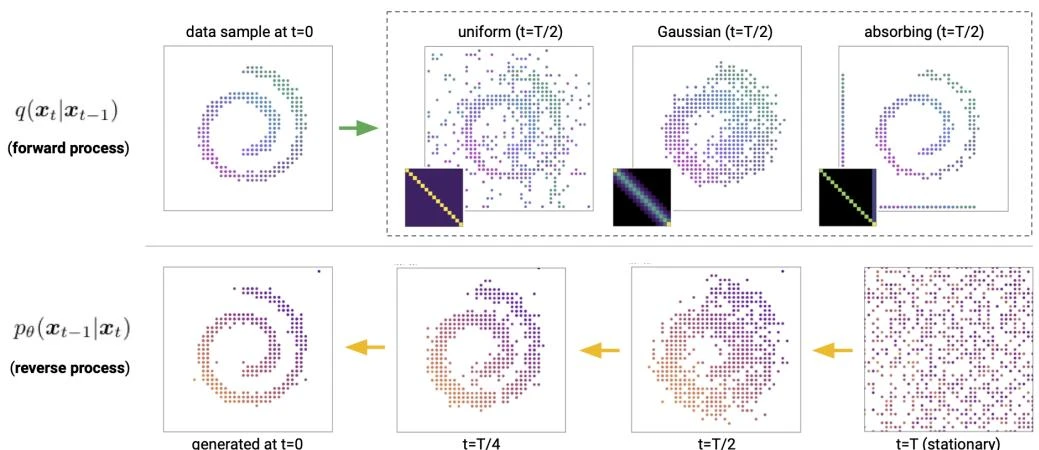
This paper introduces Discrete Denoising Diffusion Probabilistic Models (D3PMs), which generalize diffusion to discrete state-spaces using structured Markov transition matrices. D3PMs include uniform, absorbing-state, and discretized Gaussian corruption processes, drawing a connection between diffusion and masked language models.
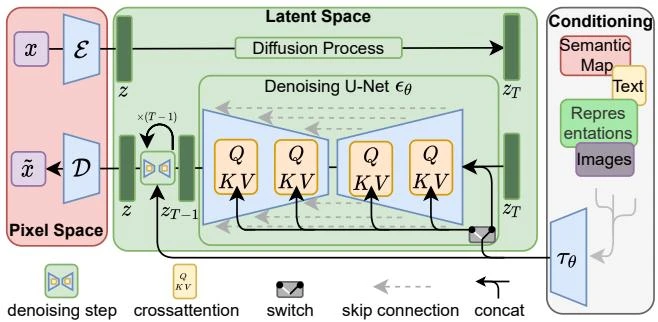
Latent Diffusion Models for High-Res Image Synthesis
This paper introduces Latent Diffusion Models (LDMs), which apply denoising diffusion in the latent space of pretrained autoencoders. By separating perceptual compression from generative learning and adding cross-attention conditioning, LDMs achieve FID 1.50 on Places inpainting and FID 3.60 on ImageNet class-conditional synthesis, with competitive text-to-image generation, at a fraction of the compute cost of pixel-space diffusion.
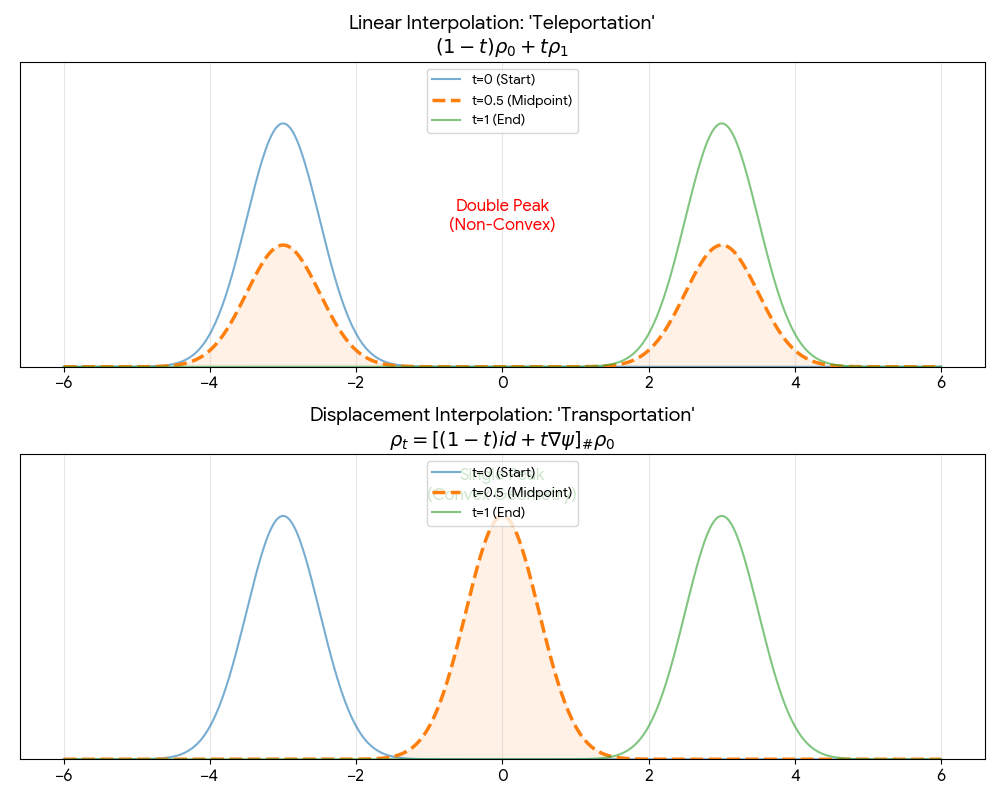
A Convexity Principle for Interacting Gases (McCann 1997)
A theoretical paper that introduces displacement interpolation (optimal transport) to establish a new convexity principle for energy functionals. It proves the uniqueness of ground states for interacting gases and generalizes the Brunn-Minkowski inequality, providing mathematical tools later used in flow matching and optimal transport-based generative models.
Building Normalizing Flows with Stochastic Interpolants
Proposes ‘InterFlow’, a method to learn continuous normalizing flows between arbitrary densities using stochastic interpolants. It avoids ODE backpropagation by minimizing a quadratic objective on the velocity field, enabling scalable ODE-based generation. On CIFAR-10, NLL matches ScoreSDE (2.99 bits per dim) with simulation-free training, though FID (10.27) trails dedicated image models (ScoreSDE: 2.92); the primary strength is tractable likelihood with efficient training cost.
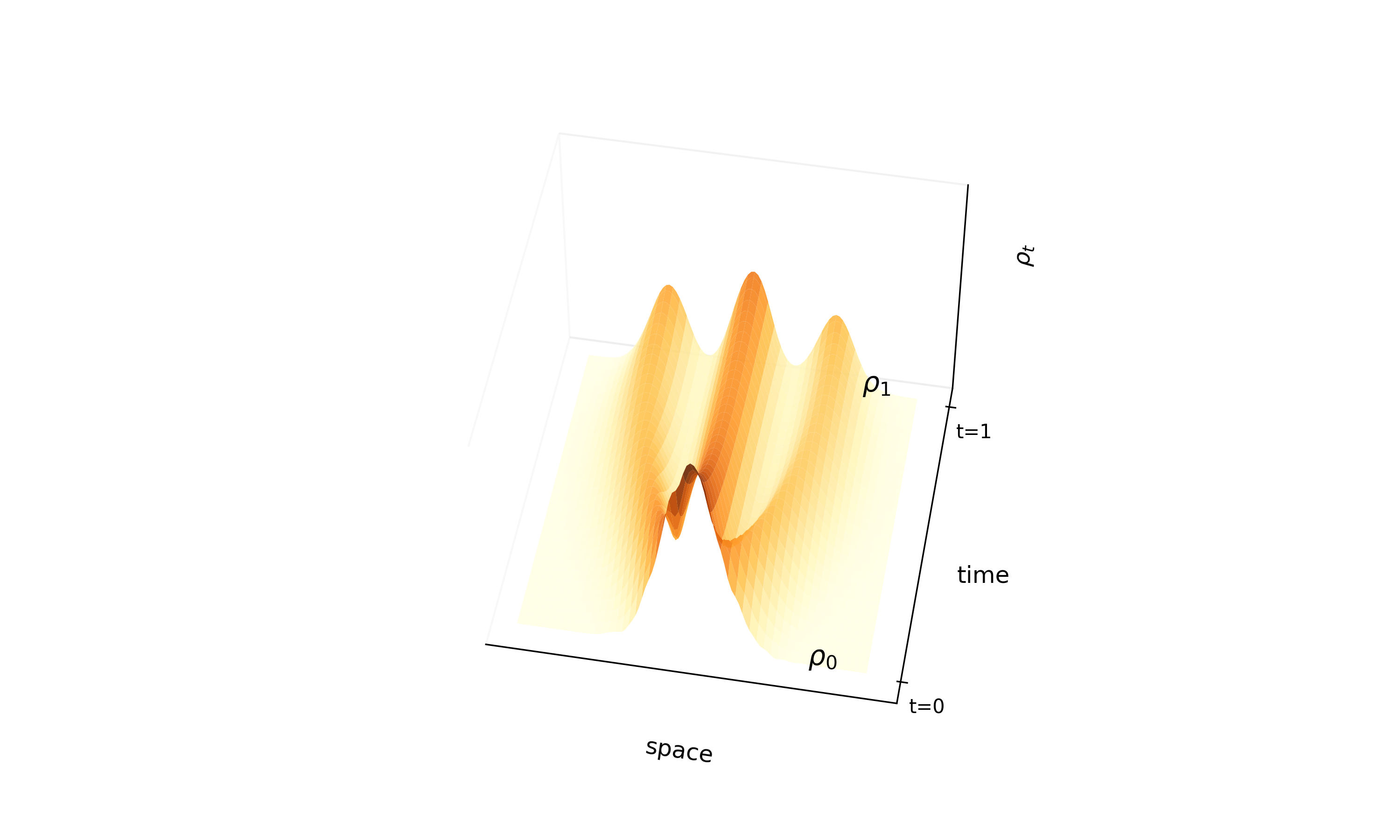
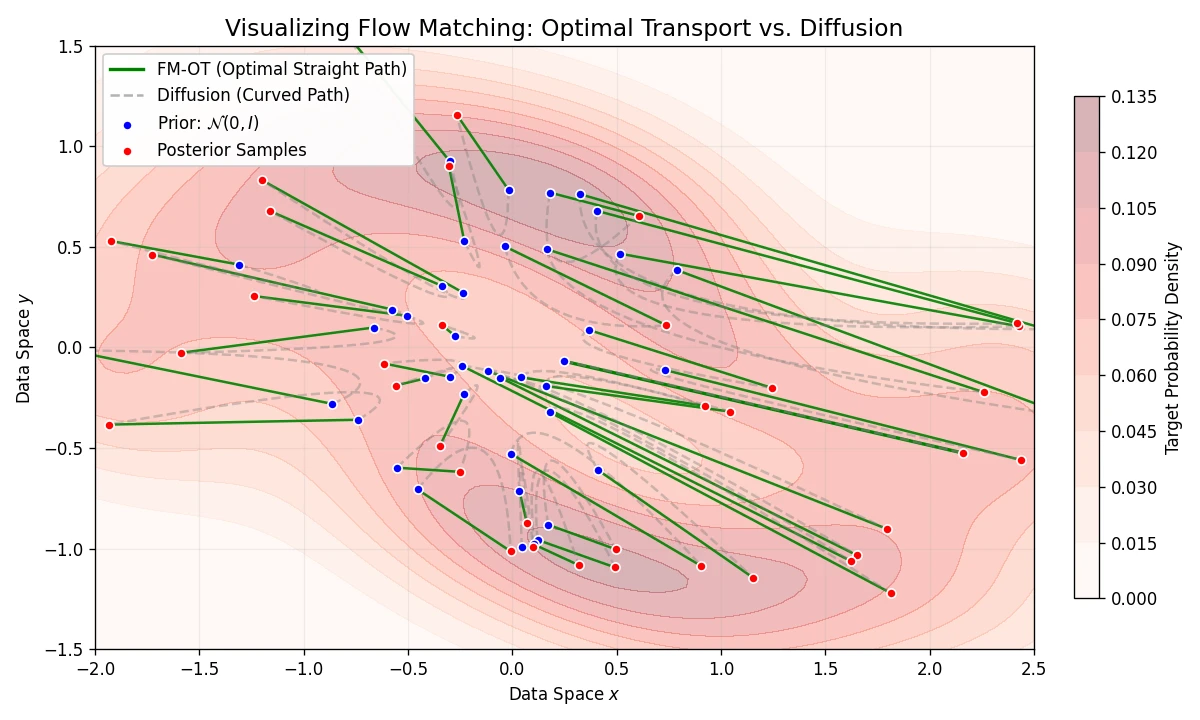
Flow Matching for Generative Modeling: Scalable CNFs
Introduces Flow Matching, a scalable method for training CNFs by regressing vector fields of conditional probability paths. It generalizes diffusion and enables Optimal Transport paths for straighter, more efficient sampling.
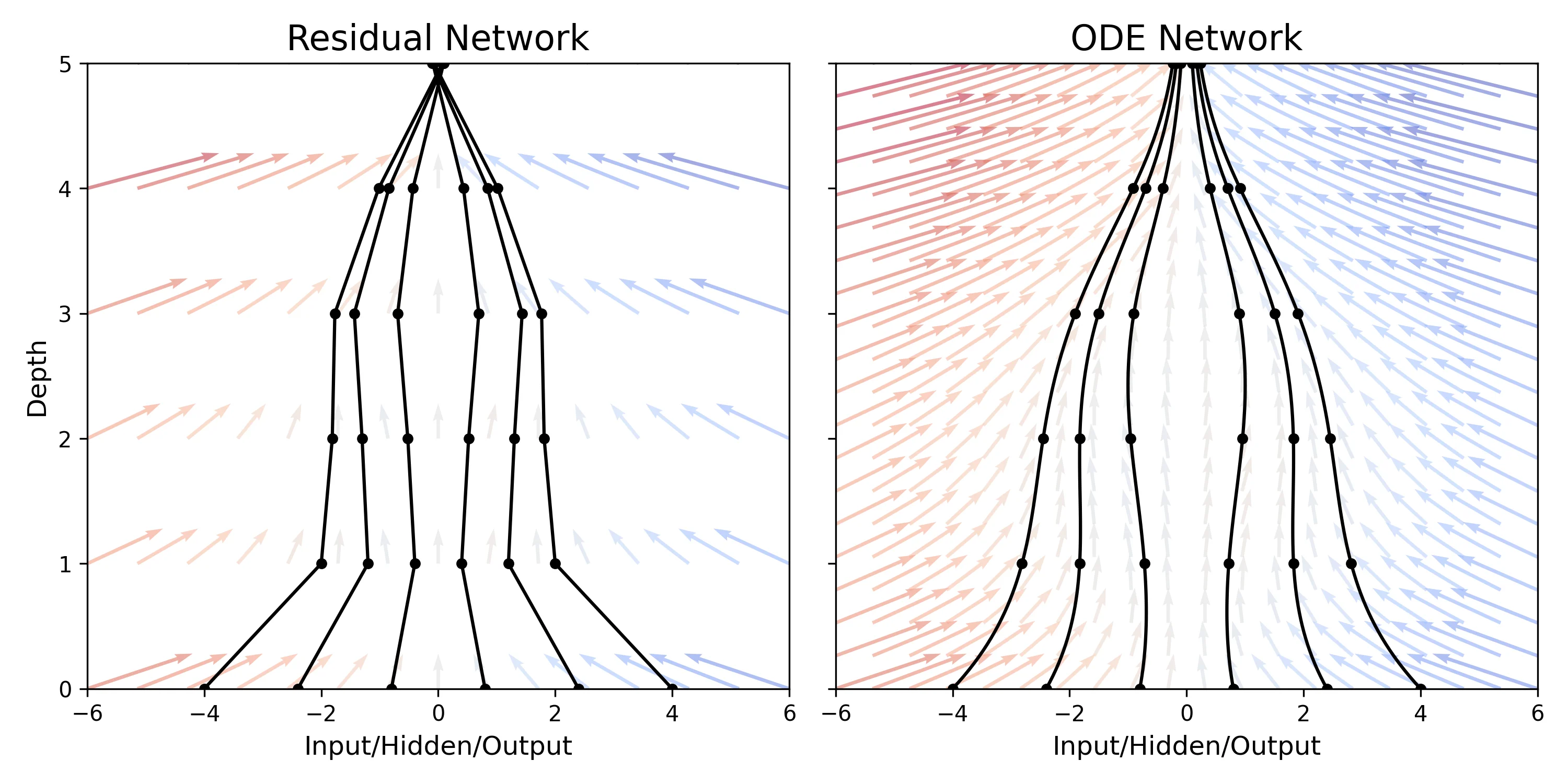
Neural ODEs: Continuous-Depth Deep Learning Models
This paper replaces discrete network layers with continuous ordinary differential equations (ODEs), allowing for adaptive computation depth and constant memory cost during training via the adjoint sensitivity method. It introduces Continuous Normalizing Flows and latent ODEs for time-series.
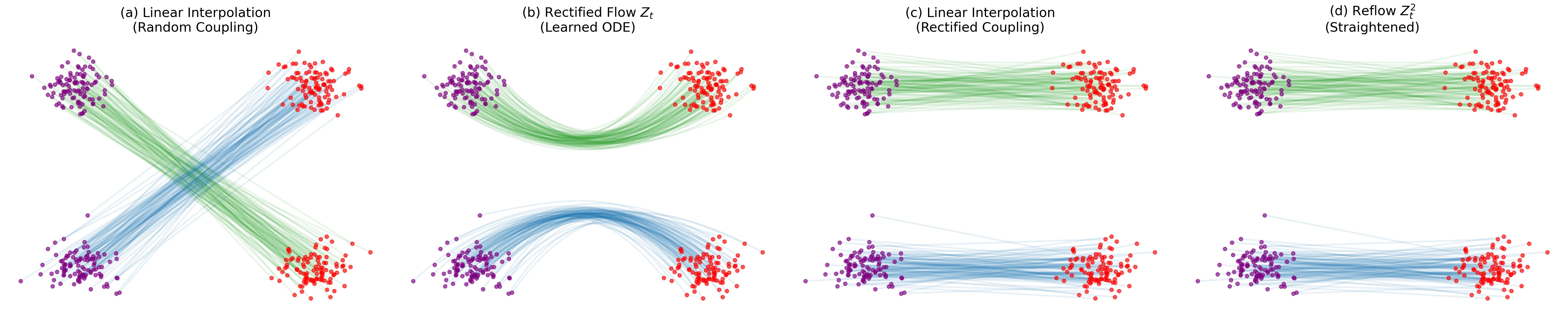
Rectified Flow: Learning to Generate and Transfer Data
Introduces ‘Rectified Flow,’ a method to transport distributions via ODEs with straight paths. Uses a ‘reflow’ procedure to iteratively straighten trajectories, enabling high-quality 1-step generation with optional lightweight distillation.
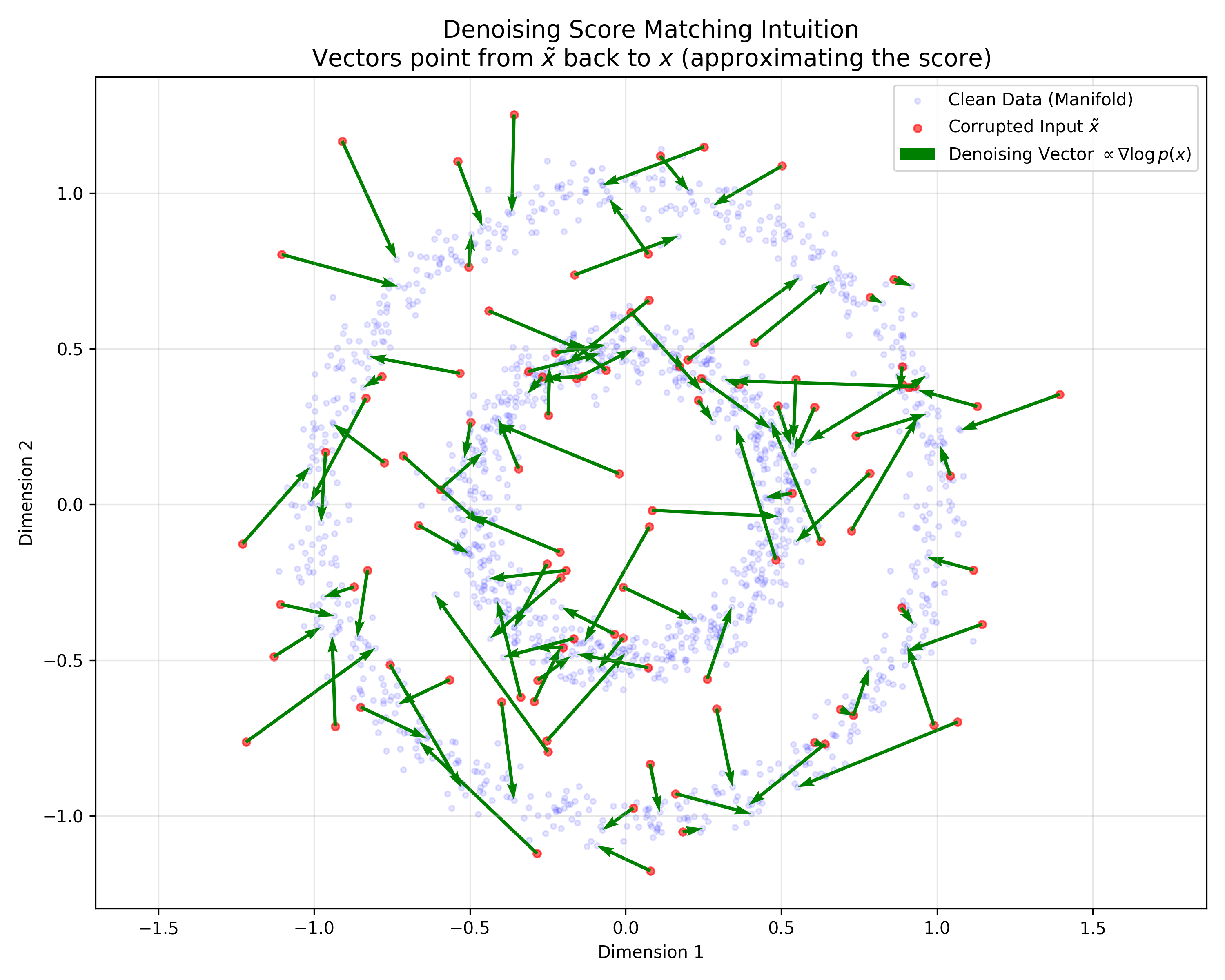
Score Matching and Denoising Autoencoders: A Connection
This paper provides a rigorous probabilistic foundation for Denoising Autoencoders by proving they are mathematically equivalent to Score Matching on a kernel-smoothed data distribution. It derives a specific energy function for DAEs and justifies the use of tied weights.
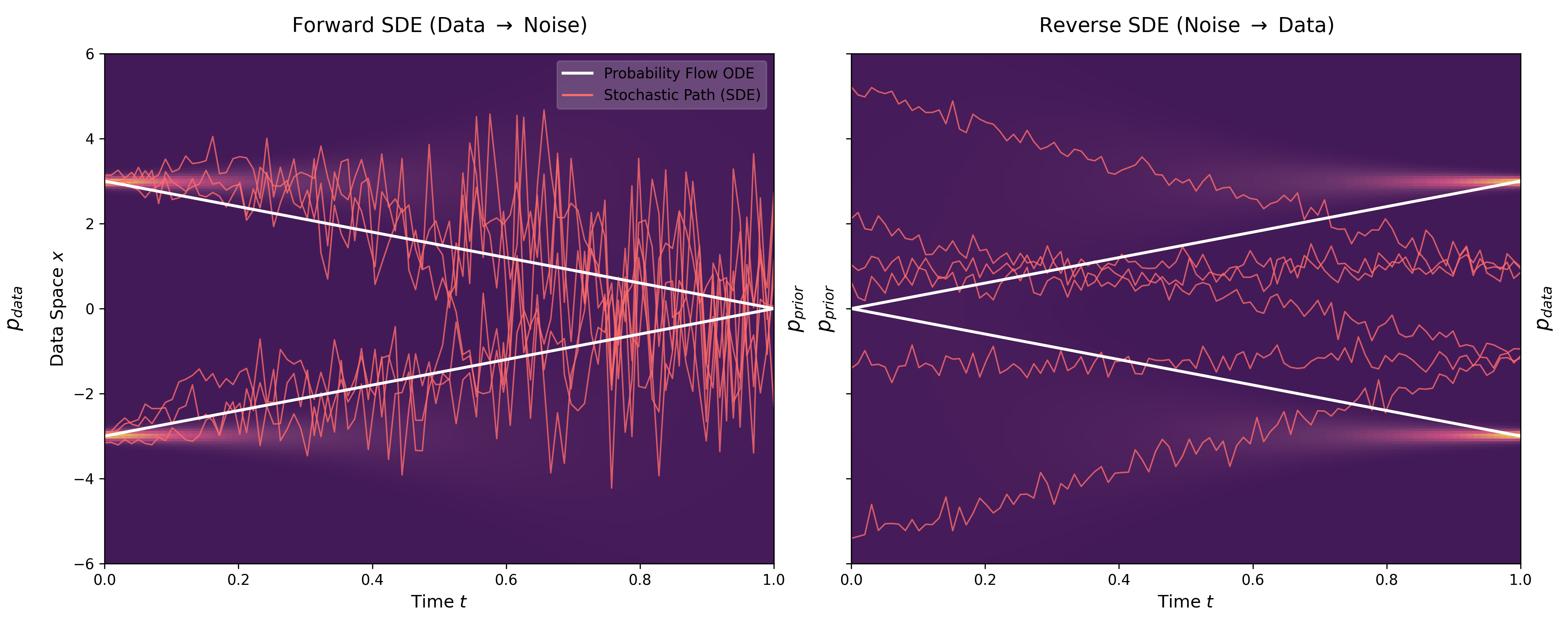
Score-Based Generative Modeling with SDEs (Song 2021)
This paper unifies previous score-based methods (SMLD and DDPM) under a continuous-time SDE framework. It introduces Predictor-Corrector samplers for improved generation and Probability Flow ODEs for near-exact likelihood computation, setting new records on CIFAR-10.
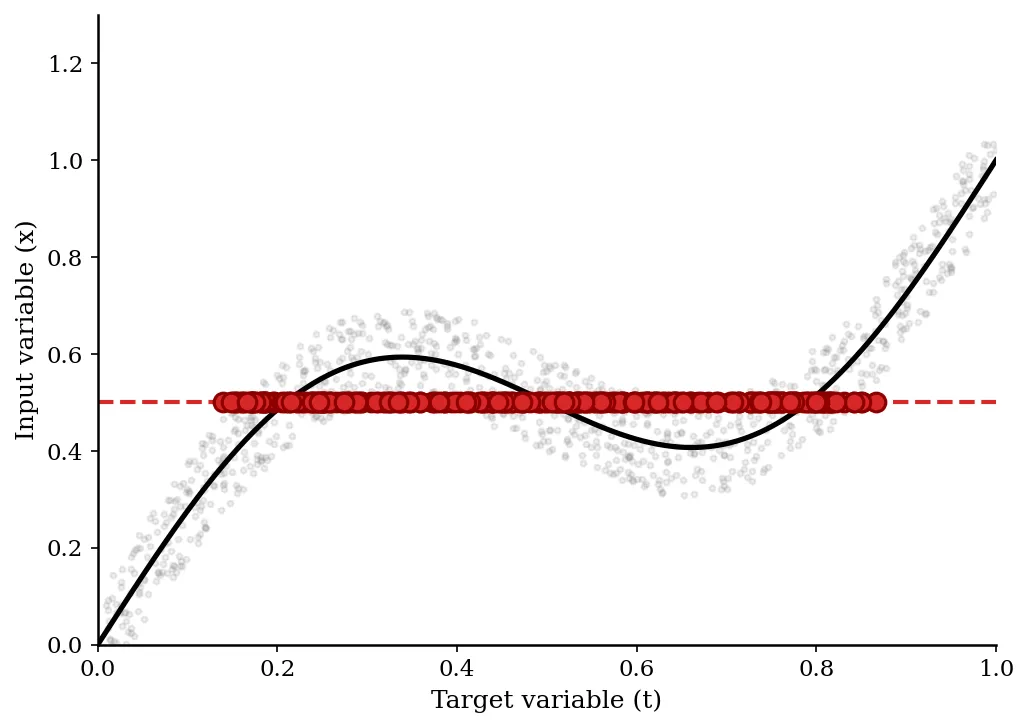
Mixture Density Networks: Modeling Multimodal Distributions
A 1994 paper identifying why standard least-squares networks fail at inverse problems (multi-valued mappings). It introduces the Mixture Density Network (MDN), which predicts the parameters of a Gaussian Mixture Model to capture the full conditional probability density.
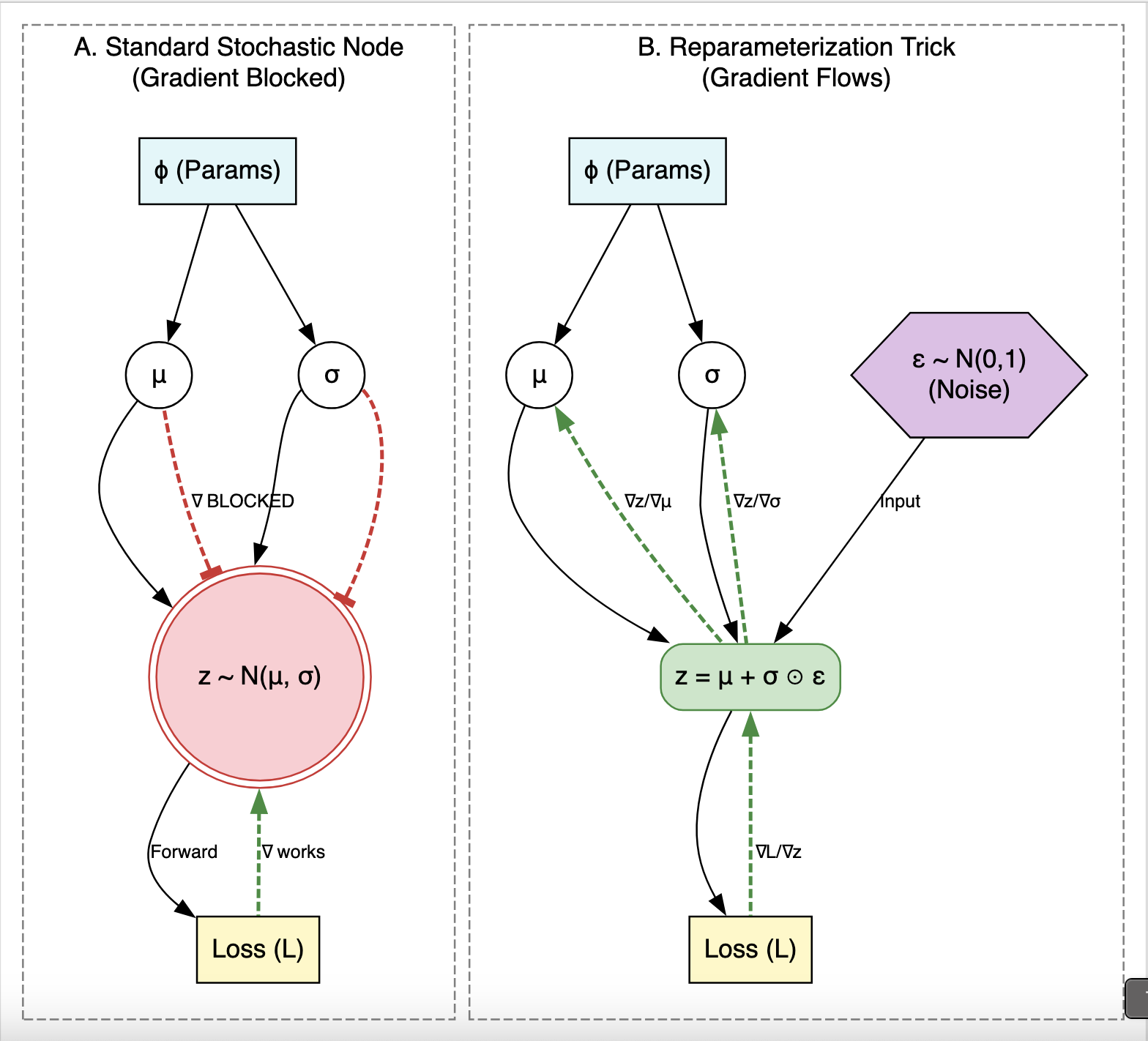
Auto-Encoding Variational Bayes: VAE Paper Summary
Kingma and Welling’s 2013 paper introducing Variational Autoencoders and the reparameterization trick, enabling end-to-end gradient-based training of generative models with continuous latent variables by moving the stochasticity outside the computational graph so that gradients can flow through a deterministic path.