
GutenOCR: A Grounded Vision-Language Front-End for Documents
GutenOCR is a family of vision-language models designed to serve as a ‘grounded OCR front-end’, providing high-quality text transcription and explicit geometric grounding.
GutenOCR is a family of vision-language models designed to serve as a ‘grounded OCR front-end’, providing high-quality text transcription and explicit geometric grounding.
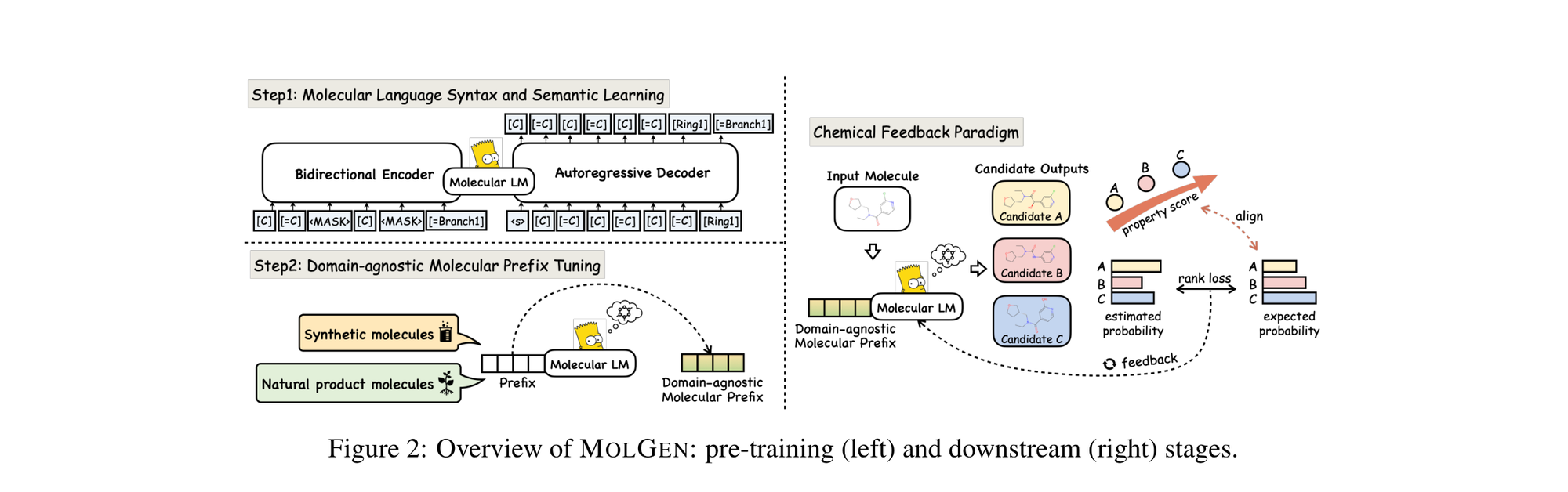
MolGen pre-trains on 100M+ SELFIES molecules, introduces domain-agnostic prefix tuning for cross-domain transfer, and applies a chemical feedback paradigm to reduce molecular hallucinations.
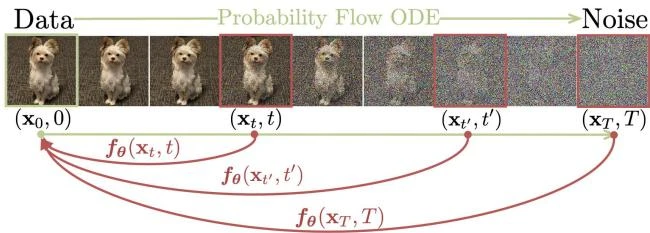
This paper introduces consistency models, a new family of generative models that map any point on a Probability Flow ODE trajectory to its origin. They support fast one-step generation by design, while allowing multi-step sampling for improved quality and zero-shot editing tasks like inpainting and colorization.
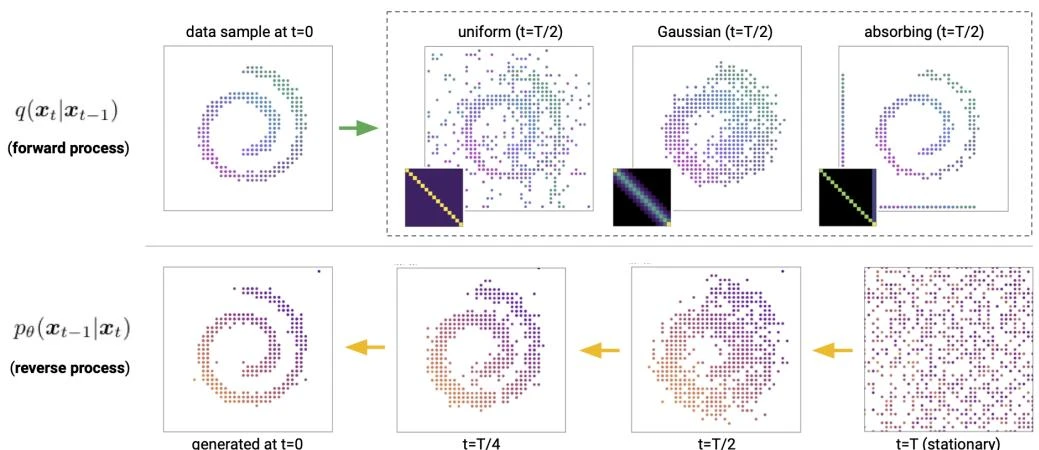
This paper introduces Discrete Denoising Diffusion Probabilistic Models (D3PMs), which generalize diffusion to discrete state-spaces using structured Markov transition matrices. D3PMs include uniform, absorbing-state, and discretized Gaussian corruption processes, drawing a connection between diffusion and masked language models.
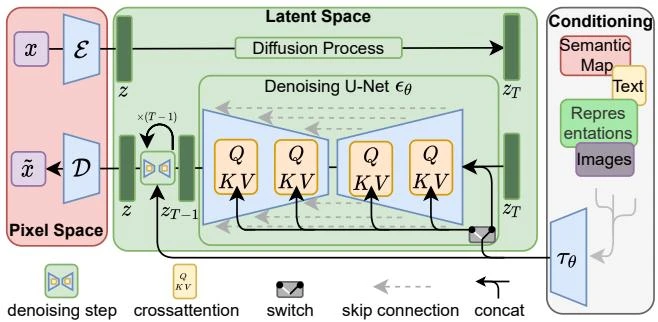
This paper introduces Latent Diffusion Models (LDMs), which apply denoising diffusion in the latent space of pretrained autoencoders. By separating perceptual compression from generative learning and adding cross-attention conditioning, LDMs achieve FID 1.50 on Places inpainting and FID 3.60 on ImageNet class-conditional synthesis, with competitive text-to-image generation, at a fraction of the compute cost of pixel-space diffusion.
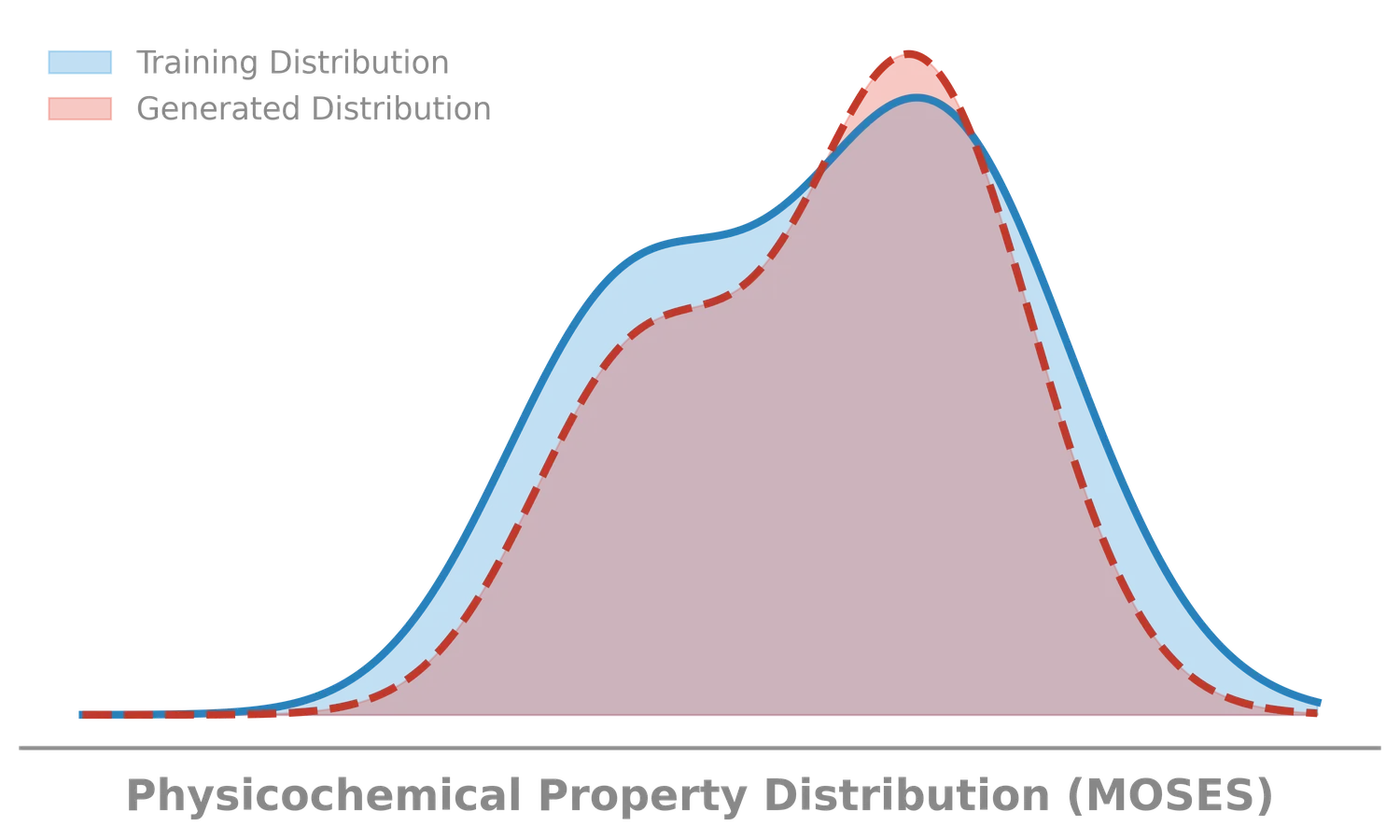
MOSES introduces a comprehensive benchmarking platform for molecular generative models, offering standardized datasets, evaluation metrics, and baselines. By providing a unified measuring stick, it aims to resolve reproducibility challenges in chemical distribution learning.
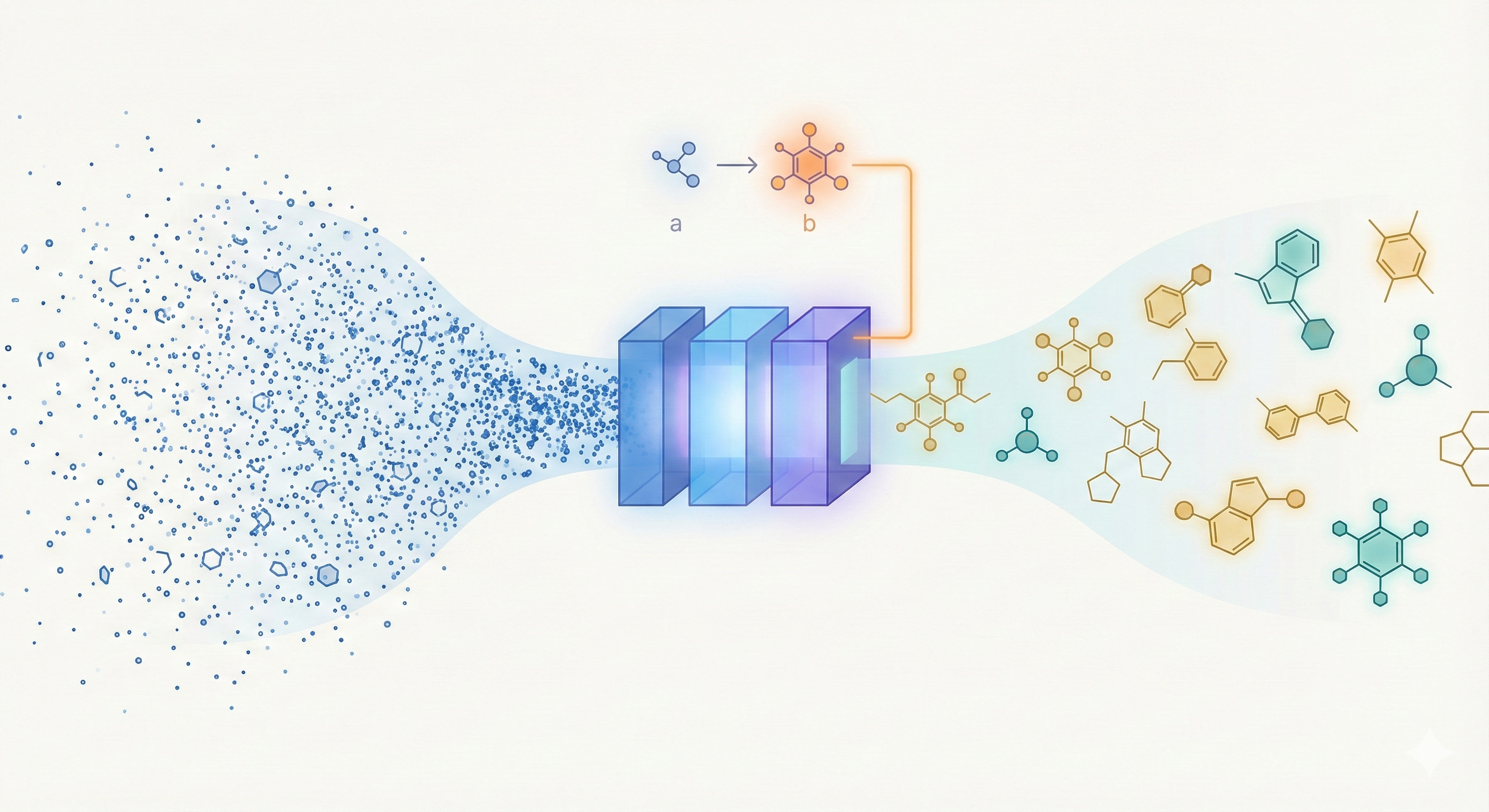
This methodological paper proposes a linear-attention transformer decoder trained on 1.1 billion molecules. It introduces pair-tuning for efficient property optimization and establishes empirical scaling laws relating inference compute to generation novelty.
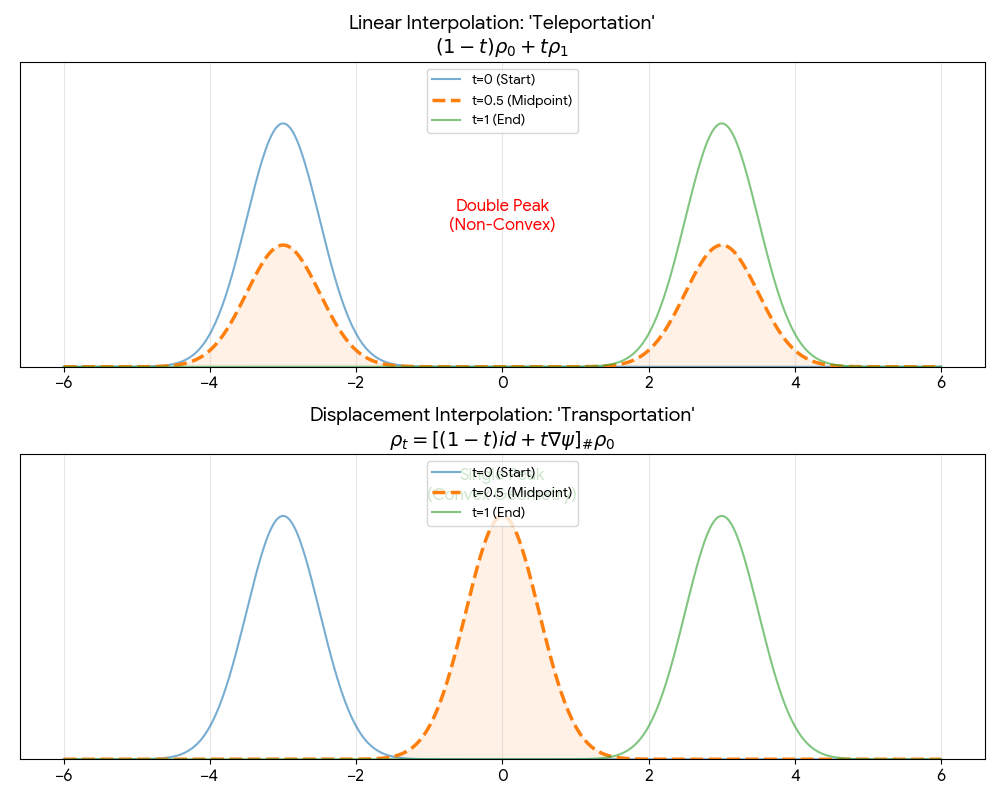
A theoretical paper that introduces displacement interpolation (optimal transport) to establish a new convexity principle for energy functionals. It proves the uniqueness of ground states for interacting gases and generalizes the Brunn-Minkowski inequality, providing mathematical tools later used in flow matching and optimal transport-based generative models.
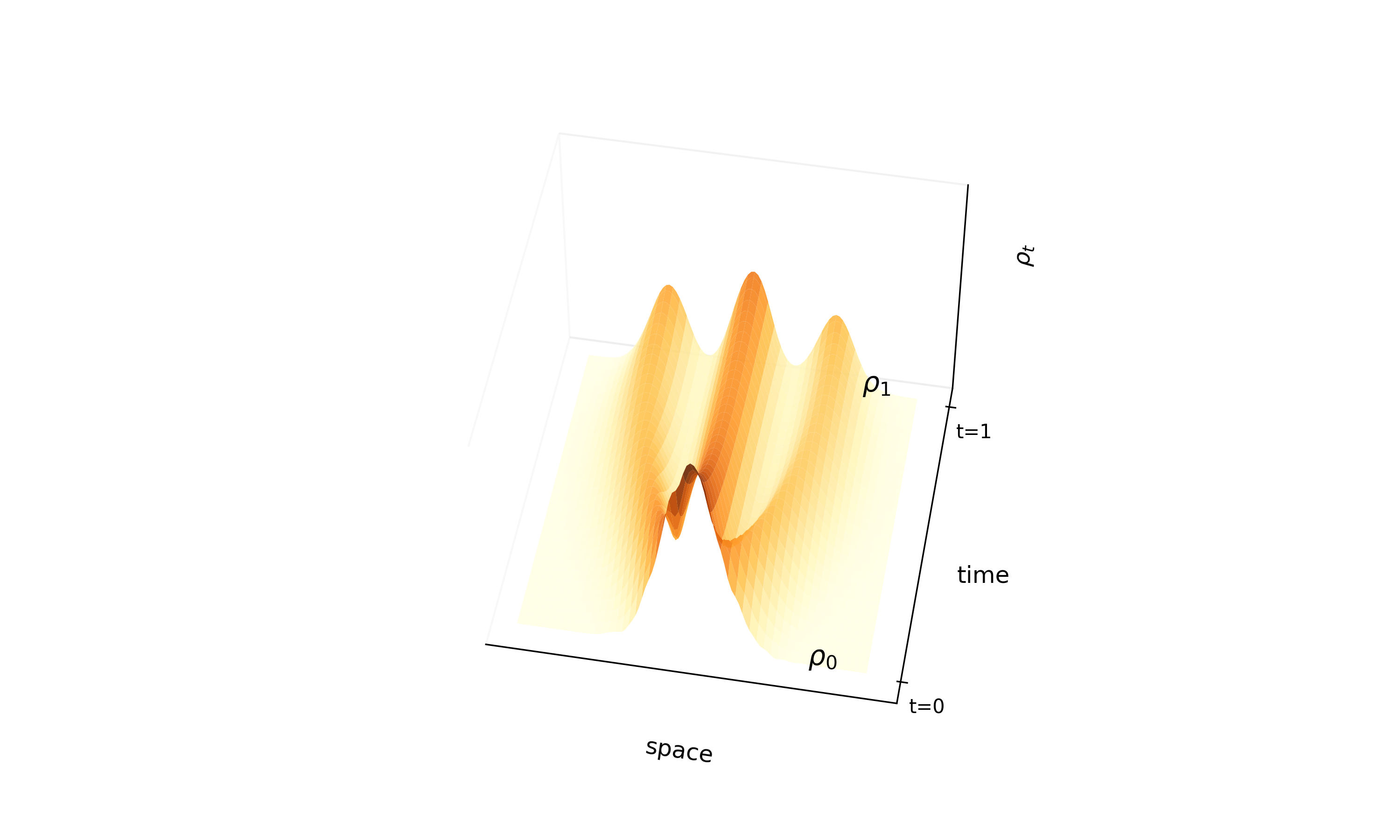
Proposes ‘InterFlow’, a method to learn continuous normalizing flows between arbitrary densities using stochastic interpolants. It avoids ODE backpropagation by minimizing a quadratic objective on the velocity field, enabling scalable ODE-based generation. On CIFAR-10, NLL matches ScoreSDE (2.99 bits per dim) with simulation-free training, though FID (10.27) trails dedicated image models (ScoreSDE: 2.92); the primary strength is tractable likelihood with efficient training cost.
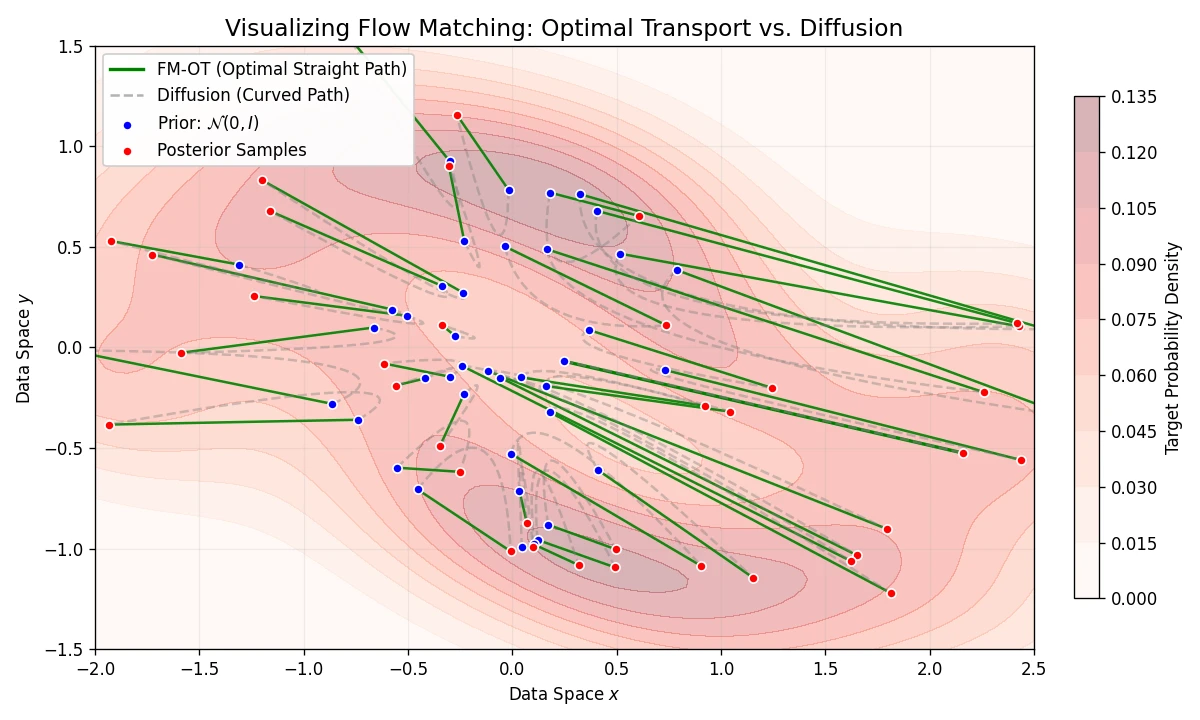
Introduces Flow Matching, a scalable method for training CNFs by regressing vector fields of conditional probability paths. It generalizes diffusion and enables Optimal Transport paths for straighter, more efficient sampling.
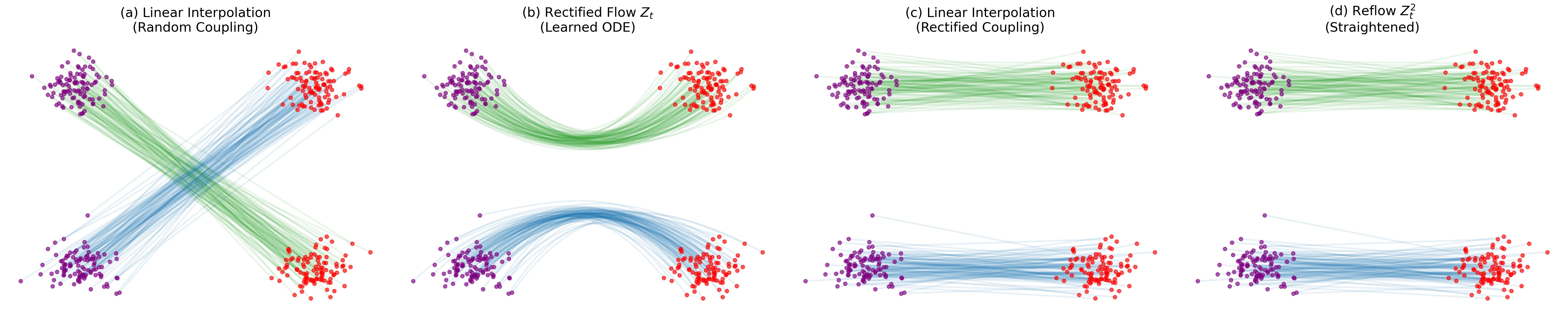
Introduces ‘Rectified Flow,’ a method to transport distributions via ODEs with straight paths. Uses a ‘reflow’ procedure to iteratively straighten trajectories, enabling high-quality 1-step generation with optional lightweight distillation.
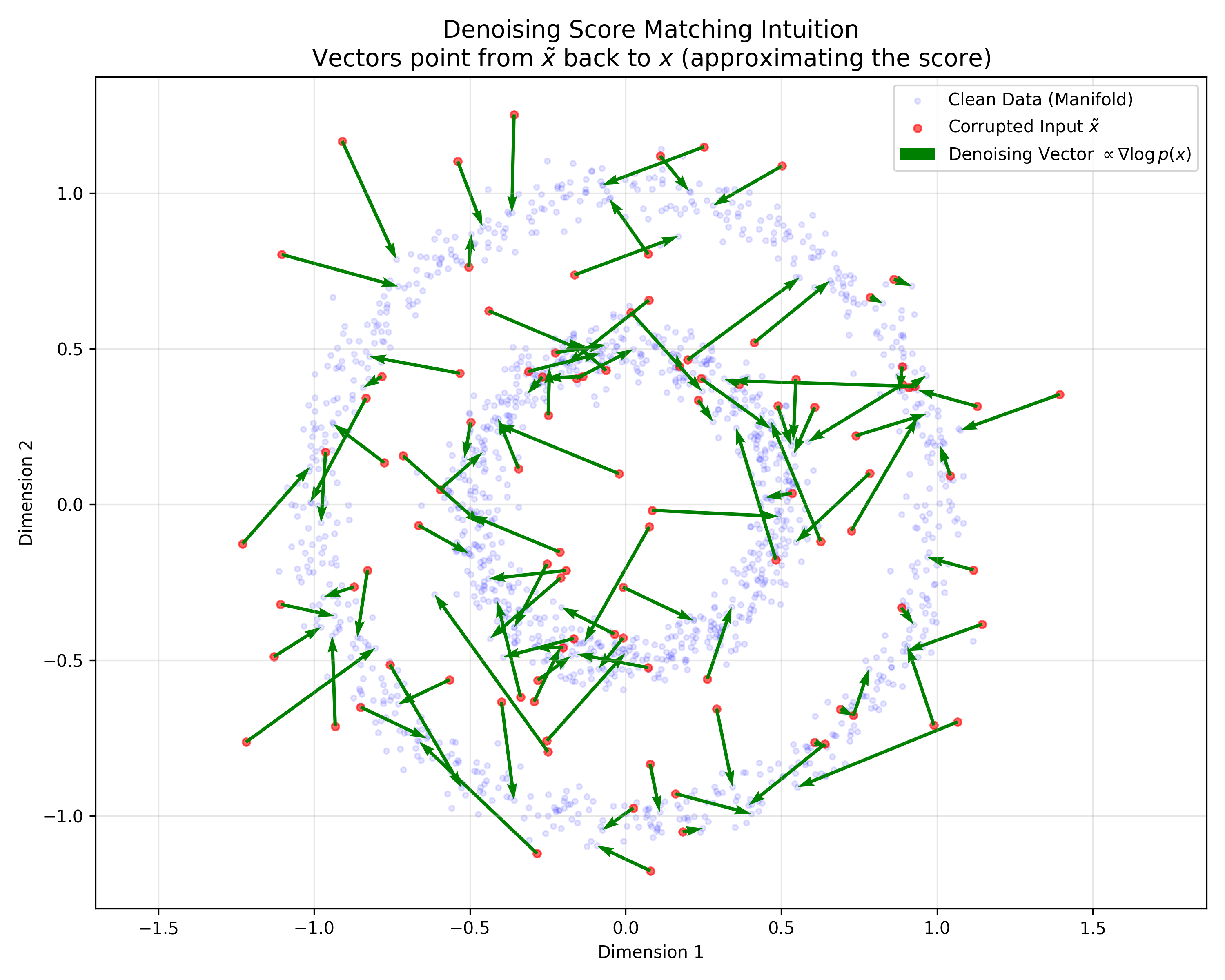
This paper provides a rigorous probabilistic foundation for Denoising Autoencoders by proving they are mathematically equivalent to Score Matching on a kernel-smoothed data distribution. It derives a specific energy function for DAEs and justifies the use of tied weights.