
GutenOCR: A Grounded Vision-Language Front-End for Documents
GutenOCR is a family of vision-language models designed to serve as a ‘grounded OCR front-end’, providing high-quality text transcription and explicit geometric grounding.
GutenOCR is a family of vision-language models designed to serve as a ‘grounded OCR front-end’, providing high-quality text transcription and explicit geometric grounding.
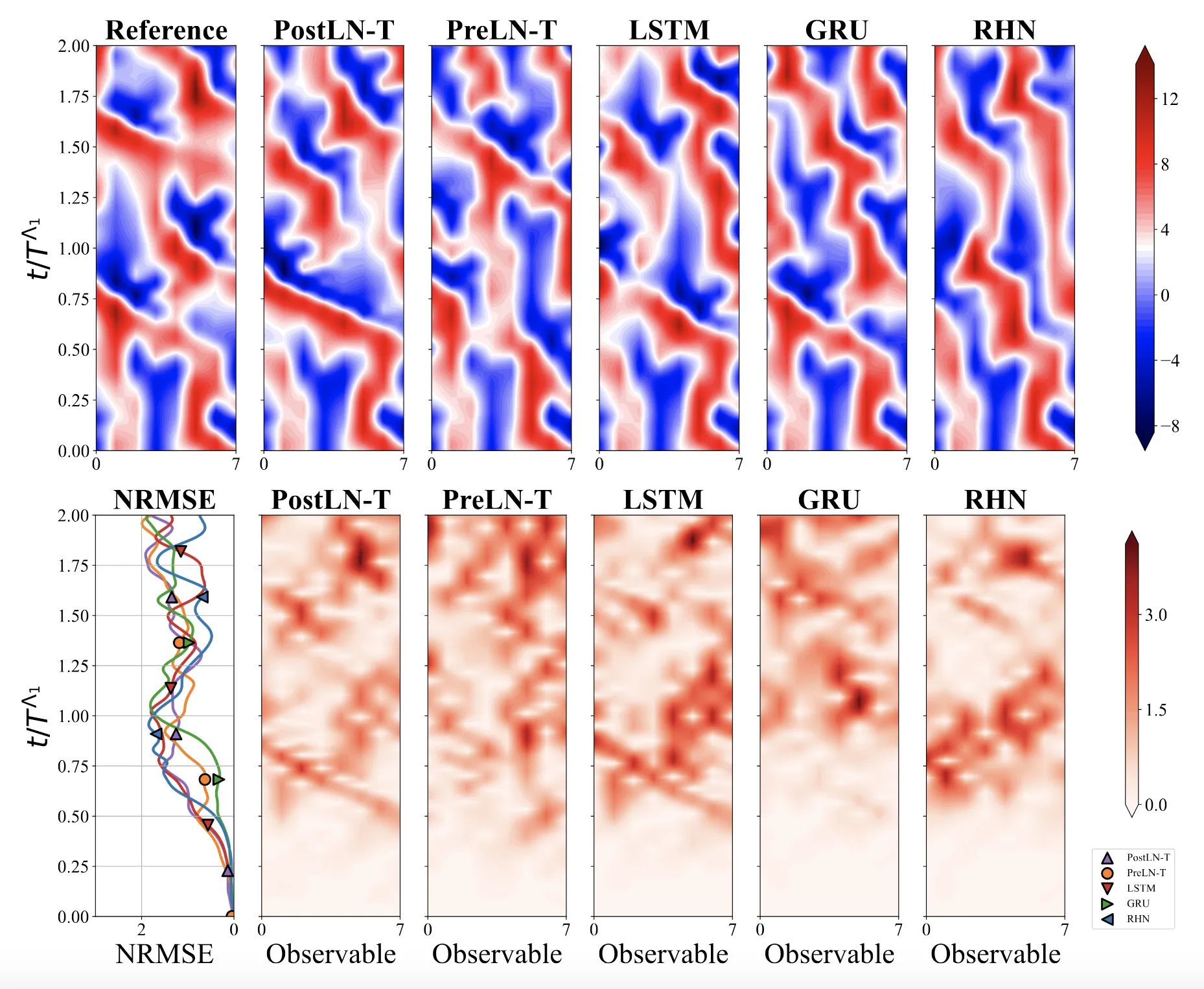
We systematically ablate core mechanisms of Transformers and RNNs, finding that attention-augmented Recurrent Highway Networks outperform standard Transformers on forecasting high-dimensional chaotic systems.
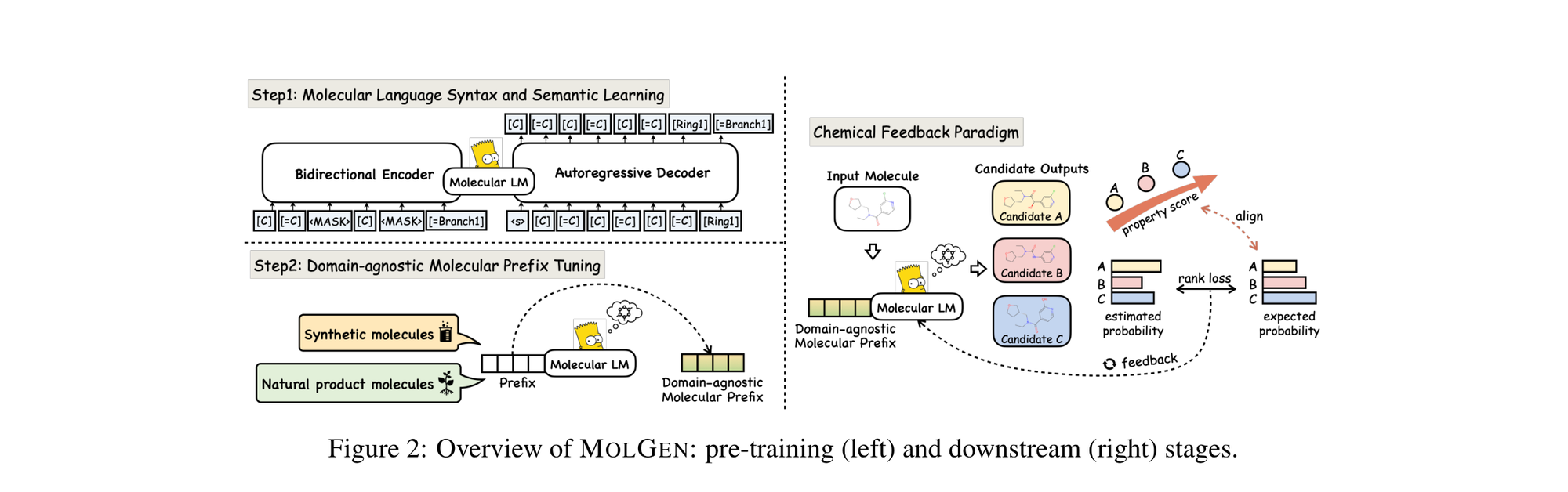
MolGen pre-trains on 100M+ SELFIES molecules, introduces domain-agnostic prefix tuning for cross-domain transfer, and applies a chemical feedback paradigm to reduce molecular hallucinations.
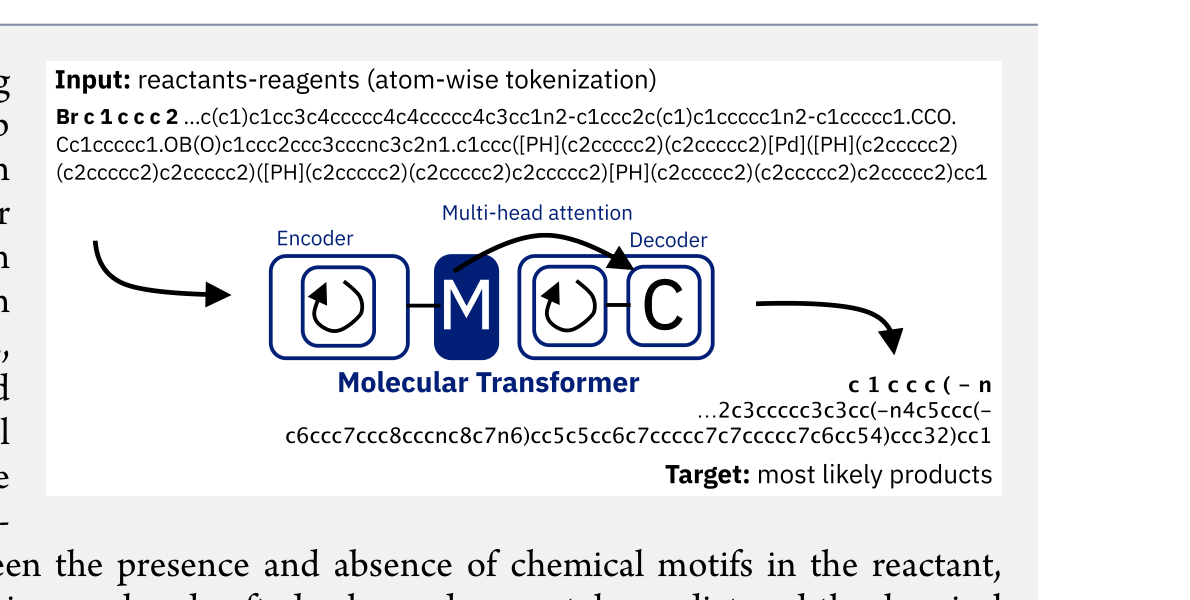
The Molecular Transformer applies the Transformer architecture to forward reaction prediction, treating it as SMILES-to-SMILES machine translation. It achieves 90.4% top-1 accuracy on USPTO_MIT, outperforms quantum-chemistry baselines on regioselectivity, and provides calibrated uncertainty scores (0.89 AUC-ROC) for ranking synthesis pathways.
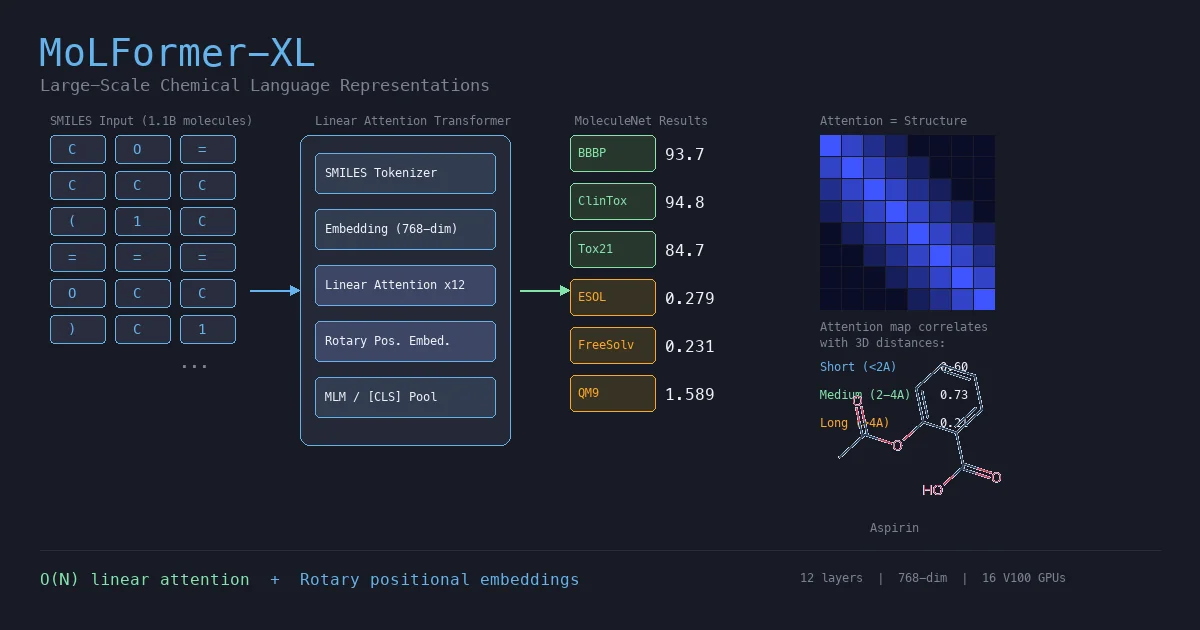
MoLFormer is a transformer encoder with linear attention and rotary positional embeddings, pretrained via masked language modeling on 1.1 billion molecules from PubChem and ZINC. MoLFormer-XL outperforms GNN baselines on most MoleculeNet classification and regression tasks, and attention analysis reveals that the model learns interatomic spatial relationships directly from SMILES strings.
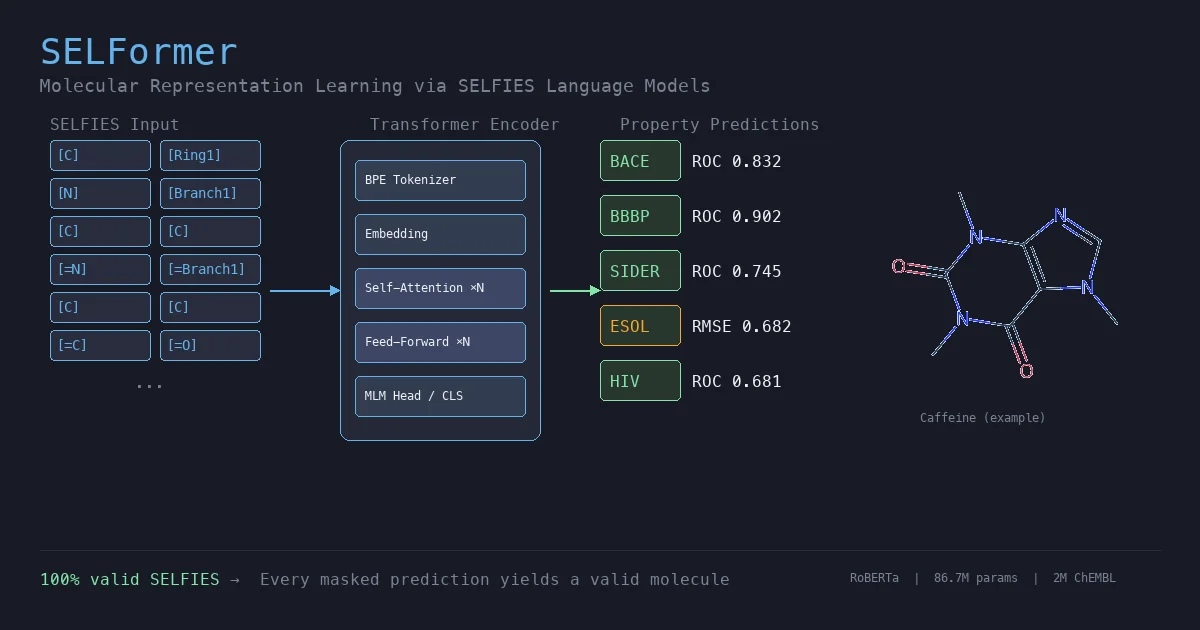
SELFormer is a transformer-based chemical language model that uses SELFIES instead of SMILES as input. Pretrained on 2M ChEMBL compounds via masked language modeling, it achieves strong classification performance on MoleculeNet tasks, outperforming ChemBERTa-2 by ~12% on average across BACE, BBBP, and HIV.
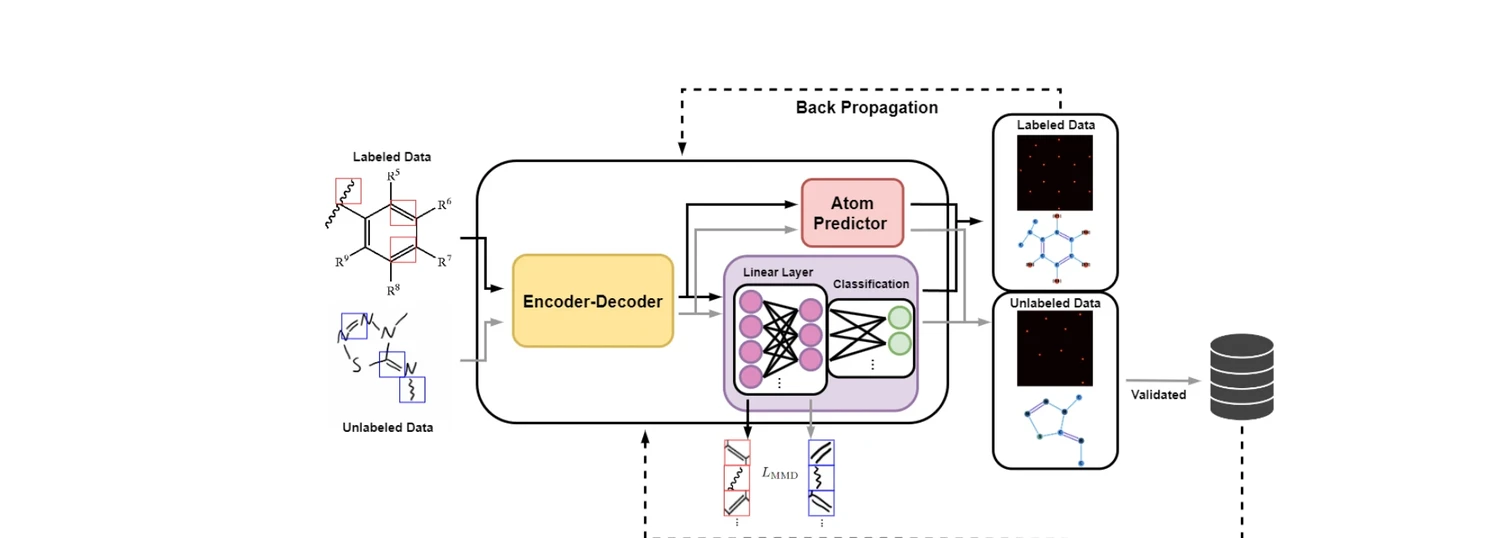
AdaptMol combines an end-to-end graph reconstruction model with unsupervised domain adaptation via class-conditional MMD on bond features and SMILES-validated self-training. Achieves 82.6% accuracy on hand-drawn molecules (10.7 points above prior best) while maintaining state-of-the-art results on four literature benchmarks, using only 4,080 real hand-drawn images for adaptation.
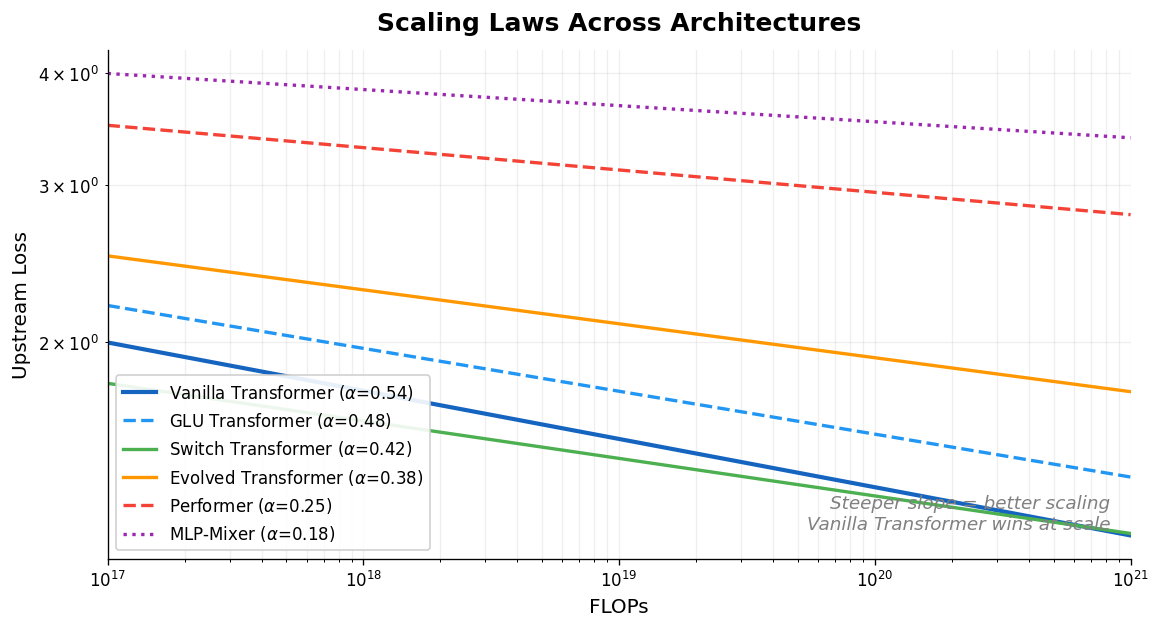
Tay et al. systematically compare scaling laws across ten diverse architectures (Transformers, Switch Transformers, Performers, MLP-Mixers, and others), finding that the vanilla Transformer has the best scaling coefficient and that the best-performing architecture changes across compute regions.

Fuchs et al. introduce the SE(3)-Transformer, which combines self-attention with SE(3)-equivariance for 3D point clouds and graphs. Invariant attention weights modulate equivariant value messages from tensor field networks, resolving angular filter constraints while enabling data-adaptive, anisotropic processing.
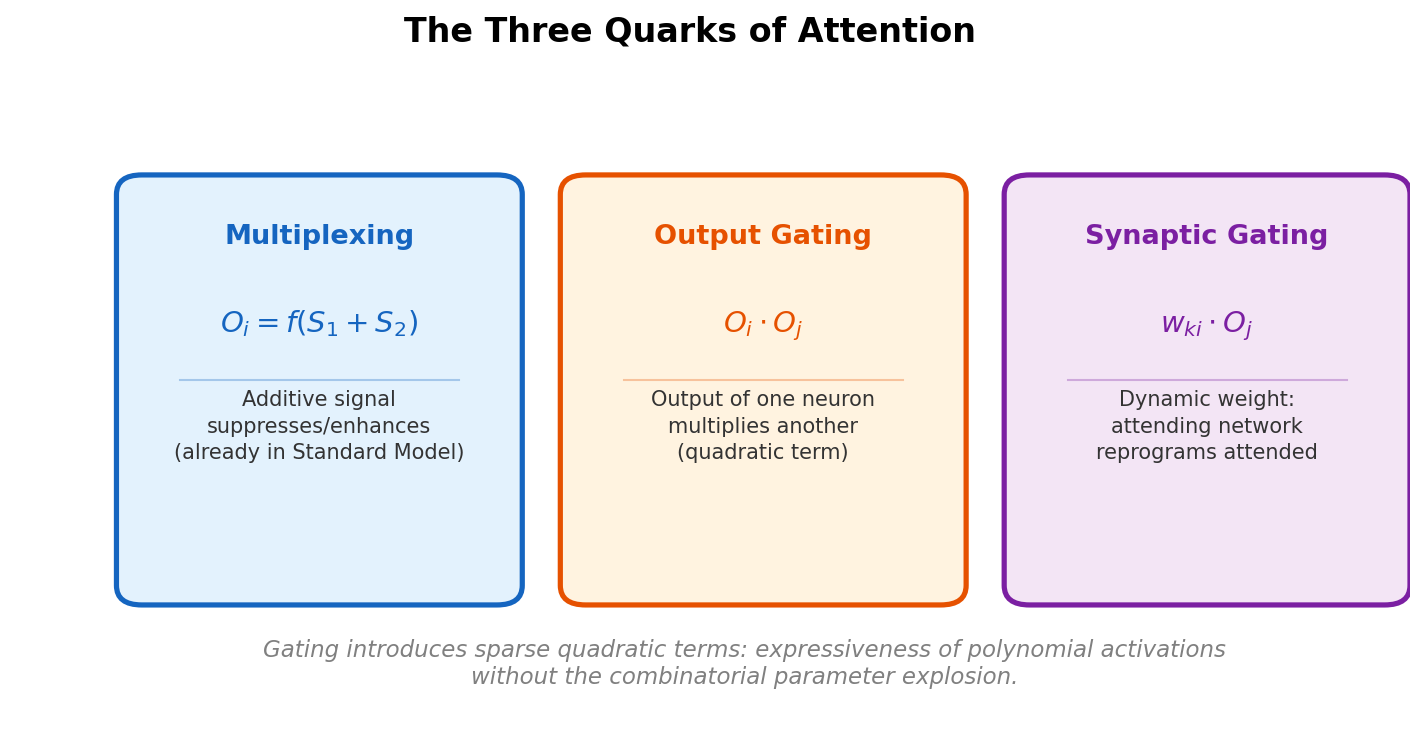
Baldi and Vershynin systematically classify the fundamental building blocks of attention (activation attention, output gating, synaptic gating) by source, target, and mechanism, then prove capacity bounds showing that gating introduces quadratic terms sparsely, gaining expressiveness without the full cost of polynomial activations.
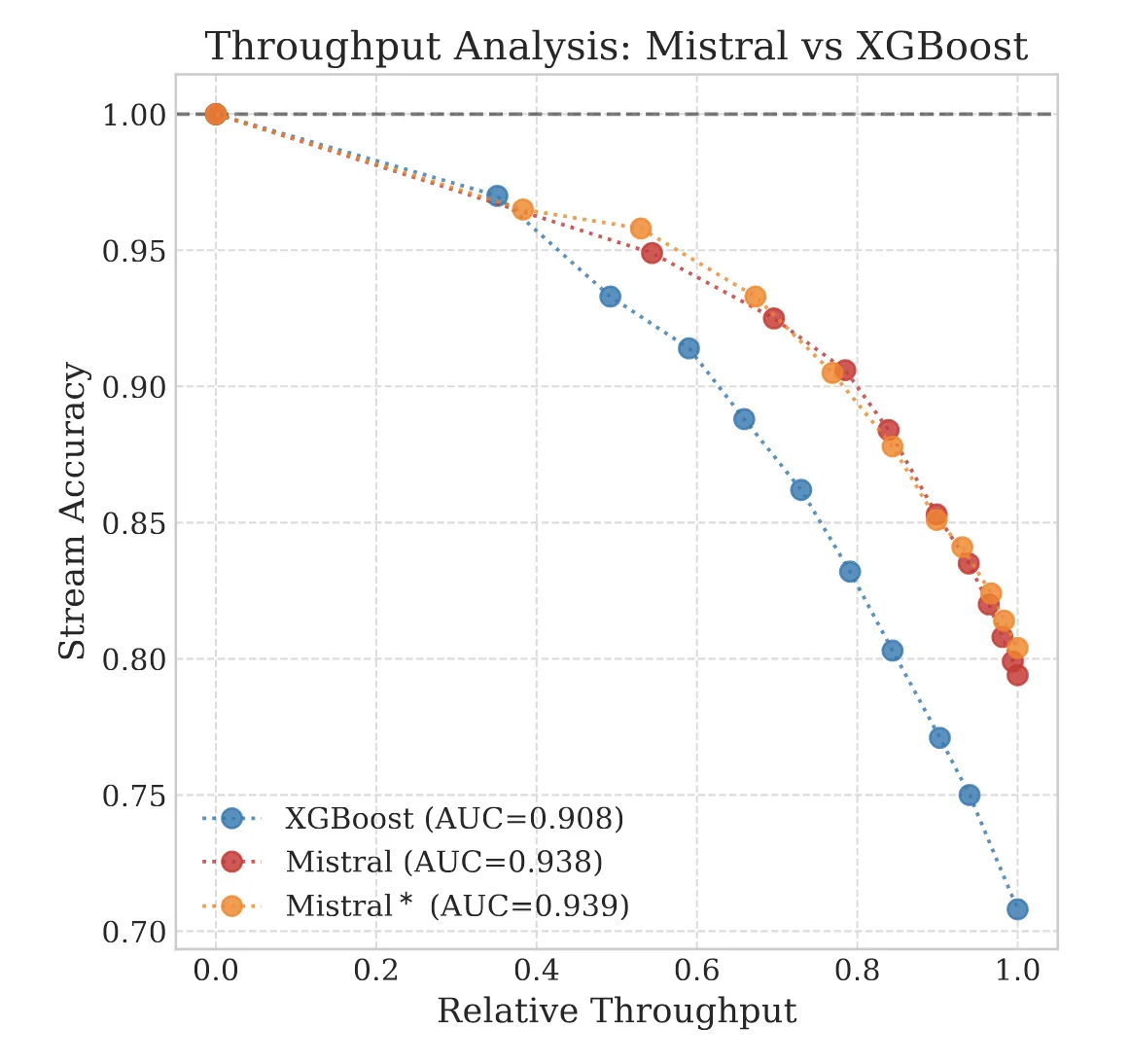
We explore the ‘Silent Failure’ mode of LLMs in production: the limits of 99% accuracy for reliability, how confidence decays in long documents, and why standard calibration techniques struggle to fix it.
We trace the history of Page Stream Segmentation (PSS) through three eras (Heuristic, Encoder, and Decoder) and explain how privacy-preserving, localized LLMs enable true semantic processing.